Deterministic and probabilistic risk
Deterministic risk considers the impact of a single risk scenario, whereas probabilistic risk considers all possible scenarios, their likelihood and associated impacts.

Deterministic approaches are used to assess disaster impacts of a given hazard scenario, whereas probabilistic methods are used to obtain more refined estimates of hazard frequencies and damages. Probabilistic assessments are characterized by inherent uncertainties, partly related to the natural randomness of hazards, and partly because of our incomplete understanding and measurement of the hazards, exposure and vulnerability under consideration.
OECD, 2012
What is the difference between deterministic and probabilistic risk?
While historical losses can explain the past, they do not necessarily provide a good guide to the future; most disasters that could happen have not happened yet. Probabilistic risk assessment simulates those future disasters which, based on scientific evidence, are likely to occur. As a result, these risk assessments resolve the problem posed by the limits of historical data. Probabilistic models therefore "complete" historical records by reproducing the physics of the phenomena and recreating the intensity of a large number of synthetic events.
In contrast, a deterministic model treats the probability of an event as finite. The deterministic approach typically models scenarios, where the input values are known and the outcome is observed.
There is overlap in deterministic and probabilistic modelling. For example, probabilistic modelling (i.e. running multiple scenarios at different probabilities of occurrence) can be used to generate a deterministic scenario; typical scenarios might include:
- Worst-case e.g. the maximum losses
- Best-case e.g. the losses that can be absorbed
- Most "likely" e.g. the losses that are most likely to occur
There are a number of problems with a deterministic approach, including the fact that it does not consider the full range of possible outcomes, and does not quantify the likelihood of each of these outcomes. Consequently, deterministic scenario planning may actually be underestimate the potential risk. In order to address this short-fall, we have to adopt a probabilistic approach.
Probabilistic risk is the chance of something adverse occurring. This method assesses the likelihood of an event(s) and it contains the idea of uncertainty because it incorporates the concept of randomness.
In the context of disaster risk, probability refers to the frequency of occurrence or the return period of losses associated with hazardous events. What do we mean by return period? Take the following example adapted from the UNISDR Global Assessment Report 2015:
The figure shows a record 1000 years of losses of different sizes (magnitudes) - nine events exceeded a loss of '60' over that period. The time period between the nine losses ranges from sixty years to 200 years, meaning that on average losses of a magnitude of 60 were exceeded every 100 years - the return period of this loss. Put simply, the 100-year return period loss (the magnitude 60 in our example) occurs, on average, once every 100 years. As the figure shows, the return period does not mean that the loss occurs every 100 years. Likewise, it does not mean that if the loss occurred today that it would not recur for another 100 years. The return period represents the annual probability of having a loss of this size every year. The annual probability of exceeding a loss characterized by a 100-year return period is 1% - the inverse of the return period (1/100*100).
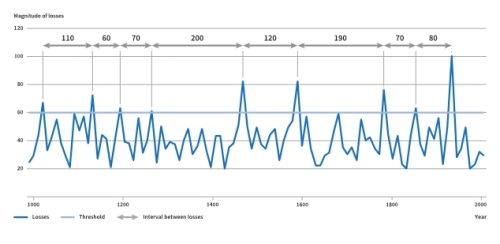
Return periods UNISDR (2015a)
Whether we use a deterministic or probabilistic approach often depends on the type of question to be answered and disaster risk management decision to be made.
We would use a probabilistic approach to determine the likelihood of a number of different events. We might adopt a deterministic approach to test an evacuation plan or mitigation strategy against a selected event. However, even if we are interested in knowing a specific risk scenario for a specific event, we can obtain this from a probabilistic assessment. In fact, probabilistic approaches allow us to identify and model scenarios whilst also accounting for their return period. Measuring the likelihood of events means that decision-makers are more informed and better able to select appropriate strategies for different scenarios, e.g. risk reduction in the case of extensive risks and risk transfer in the case of more high-impact (but less likely) events.
Assessing risk probabilistically remains a challenge, particularly because of the number of factors to account for and because risk is not static and is increasingly influenced by a number of other drivers, including climate change. But probabilistic risk assessments are increasingly becoming the standard for disaster risk assessment because they are the more comprehensive approach. These assessments provide us with a means of quantifying the impact and likelihood of events, while also accounting for the associated uncertainty.
What is uncertainty?
Few findings from natural and social science are 100% certain, owing to the natural randomness of hazards and the fact that information and understanding of processes is incomplete. In spite of this, we still have to make decisions for building resilience.
A risk model can produce a very precise result—it may show, for example, that a 1-in-100-year flood will affect 388,123 people—but in reality the accuracy of the model and input data may provide only an order of magnitude estimate. Similarly, sharply delineated flood zones on a hazard map do not adequately reflect the uncertainty associated with the estimate and could lead to decisions such as locating critical facilities just outside the flood line, where the actual risk is the same as if the facility was located inside the flood zone.
We should not be apprehensive of using information that is uncertain so long as any decisions and actions based upon the information are made with a full understanding of the associated uncertainty and its implications. It should be remembered that uncertainty will usually promote an analytical debate that should lead to robust decisions, which is a positive manifestation of uncertainty. Credible scientific information will also have any associated uncertainty clearly presented.
How do we model deterministic and probabilistic risk?
We model risk both deterministically and probabilistically using a series of components (sometimes called modules) for hazard, exposure, vulnerability and loss (or impact). In deterministic models, the output of the model is fully determined by the parameter values and the initial values, whereas probabilistic (or stochastic) models incorporate randomness in their approach. Consequently, the same set of parameter values and initial conditions will lead to a group of different outputs. We can also use probabilistic risk models to do a deterministic analysis by entering the parameters of the specific hazard event.
Hazard catalogues and event sets can be used with risk models in a deterministic or probabilistic manner. Deterministic risk models are used to assess the impact of specific events on exposure. Typical scenarios for a deterministic analysis include renditions of past historical events, worst-case scenarios, or possible events at different return periods. For example, a deterministic risk (or impact) analysis will provide a robust estimation of the potential building damage, mortality/morbidity, and economic loss from a single hazard scenario. Risk models are used in a probabilistic sense when an event set contains a sufficient number of events for the estimate of the risk to converge at the longest return period, or the smallest probability, of interest.
We cannot wholly rely on our knowledge of past events to anticipate future risk, because some disasters that could happen have not yet happened.
A probabilistic approach minimizes these limitations. It uses historical events, expert knowledge, and theory to simulate events that can physically occur but are not represented in the historical record. A probabilistic approach can generate a catalogue of all possible events, the probability of occurrence of each event, and their associated losses. As such, they provide a more complete picture of the full spectrum of future risks than is possible with historical data. While the scientific data and knowledge used is still incomplete, provided that their inherent uncertainty is recognized, these models can provide guidance on the likely “order of magnitude” of risks.
The results of probabilistic risk models are normally presented in terms of standard measures (metrics) such as average annual loss (AAL). AAL is the expected average loss per year considering all the events that could occur over a long time frame. It is a compact metric with a low sensitivity to uncertainty. Unlike historical estimates, AAL takes into account all the disasters that could occur in the future, including very intensive losses over long return periods, and thus overcomes the limitations associated with estimates derived from historical disaster loss data. Most probabilistic risk assessments have been developed commercially for the insurance industry and cover specific risks, mainly in higher-income countries. However, they are rarely accessible and are based on proprietary models. While more and more public-domain risk models are now being developed, the use of different methodologies and data sets makes comparison difficult.
A second output is the probable maximum loss (PML) for different return periods. PMLs can be expressed as the probability of a given loss amount being exceeded over different periods of time. Thus, even in the case of a thousand-year return period, there is still a 5% probability of a PML being exceeded over a 50-year time frame. This metric is relevant, for example, to the planners and designers of infrastructure projects, where investments may be made for an expected lifespan of 50 years.
In the development of risk models, many different data sets are used as input components. The level of uncertainty is directly linked to the quality of the input data. In addition, there is also random uncertainty that cannot be reduced. On many occasions during model development, expert judgment and proxies are used in the absence of historical data, and the results are very sensitive to most of these assumptions and variations in input data. As such, outputs of these models should be considered indicators of the order of magnitude of the risks, not as exact values. Better data quality and advances in science and modelling methodologies reduce the level of uncertainty, but it is crucial to interpret the results of any risk assessment against the backdrop of unavoidable uncertainty.
Last updated on: 18 January 2024
Related stories
What’s a 100-year flood? A hydrologist explains
"A 100-year flood, like a 100-year storm, is one so severe it has only a 1% chance of hitting in any given year."
More people exposed to low-probability coastal flooding than previously expected
"Accounting for tropical cyclones more than doubles the global population exposed to low-probability coastal flooding."
Probability analysis improves hazard assessment
"Estimating the likelihood of occurrence and frequency is an important science to help people plan and prepare for future events."
